Compte rendu Nantes Monitoring mai 2017

Voici un compte rendu du Meetup Nantes Monitoring de mai 2017
Présente ta stack
Léo / Matlo
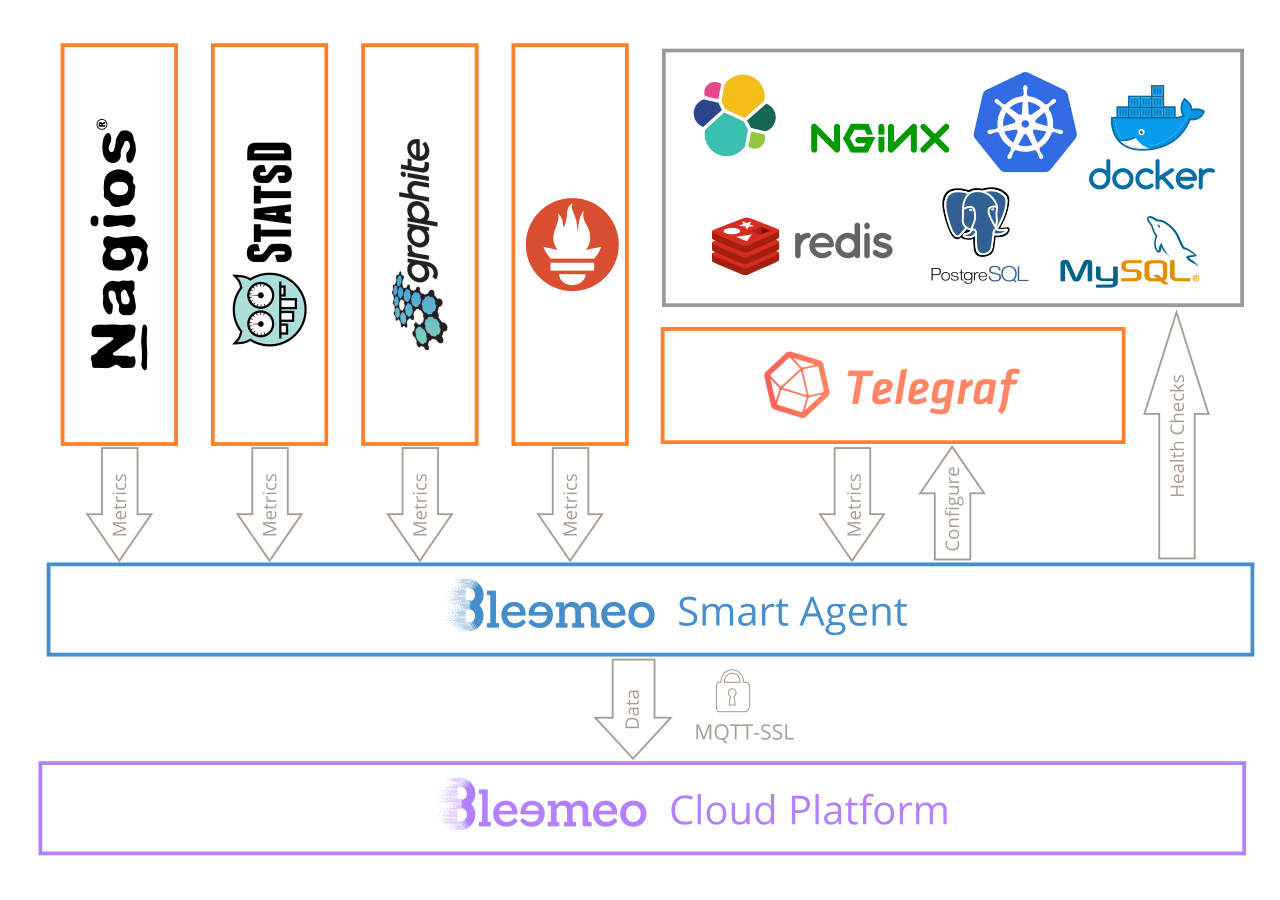
Léo de Matlo nous a présenté son utilisation de prometheus https://prometheus.io/ . Matlo a commencé à migrer vers une solution SASS (monitoring as a service) chez https://bleemeo.com/ (entreprise Toulousaine). La stack de bleemeo est décrite sur stackshare: https://stackshare.io/bleemeo/bleemeo. L'agent de bleemeo est publié en logiciel libre https://github.com/bleemeo/bleemeo-agent et repose sur telegraf https://github.com/influxdata/telegraf . Bleemeo semble utiliser MQTT-SSL pour remonter les métriques permettant ainsi un usage raisonnable des connexions réseau (cf diagramme https://bleemeo.com/features/).
Emeric / OasisWork
Arthur / Logilab
Quels outils choisir pour son monitoring ?
Exercice difficile, nous avons listé les produits connus par les participants puis un certain nombres de critères de choix, et puis nous avons rempli (partiellement) un tableau en discutant de chaque point.
Produits
- nagios
- shinken
- icinga
- sensu
- prometheus
- ELK
- packet beats
- file beats
- zabbix
- centreon
- check-mk
- ganglia
- statsd
- graphite
- influxdb
- telegraf
- cadvisor
- graylog
- rsyslog
- splunk
- thruk
- collectd
- metrics(java)
- logentries
- datadog
- bleemeo
- prtg
- munin
- smokeping
- fluentd
- dynatrace
- OMD
(liste non-exhaustive, forcément... )
Critères
- language
- prix
- age
- maintenu
- communauté
- scalable
- facilité de mise en place (pkgs, devops, etc.)
- champs d'application
- push / pull architecture
- configuration - format
- configuration - serveur/agent
- open core
- securité
- IOT ready
- modularité / plugins
- interface utilisateur (UX, interface web, etc.)
- alertes
- developpement de sondes
Début de tableau
Bien evidemment, nous n'avons pas rempli la totalité du tableau, mais les échanges ont été riches d'enseignements. Voici un apercu (flou) du tableau élaboré collectivement.

Fin
En fin de meetup nous avons parlé des conférences devoxx publiés récemment https://www.youtube.com/channel/UCsVPQfo5RZErDL41LoWvk0A et des contenus sur le monitoring et l'aggrégation de logs, notamment le projet cerebro de voyage-sncf : https://github.com/voyages-sncf-technologies/cerebro